Ve zdravotnictví hraje kvalita a bezpečnost dat zásadní roli. V LOGEX jsme proto vyvinuli vlastní platformu pro správu a sledování dat, která umožňuje bezpečnou a transparentní práci s citlivými informacemi. Jak celý systém funguje a jak zajišťujeme jeho spolehlivost? Čtěte dál.
Ve společnosti LOGEX umožňujeme našim zákazníkům – zejména nemocnicím a výzkumným institucím – vzájemně si vyměňovat data. Ta mohou zahrnovat vše od klasické finanční analytiky až po klinická data, například o léčbě rakoviny, která následně slouží pro další výzkum.
V tomto článku se zaměříme na sledování celkového koloběhu dat skrze tzv. koncept Data Lineage, který jsme použili pro naši datovou platformu.
Proč je sledování původu dat důležité
Naším cílem je vytvořit škálovatelnou a interoperabilní datovou platformu, která uživatelům umožní pohodlně pracovat s daty – ať už jde o hromadné nahrávání, úpravy stávajících záznamů, nebo jejich využití v aplikacích třetích stran či vlastních knihovnách. Abychom mohli data spolehlivě sledovat v čase, potřebujeme znát odpovědi na otázky jako:
Odkud data pochází?
Pracujeme s daty z nemocnic, která často popisují konkrétní pacienty a jsou chráněna dle GDPR. Pokud se například pacient rozhodne svá data smazat, musíme být schopni je odstranit napříč celou platformou. Totéž platí, pokud o smazání nebo změnu požádá samotná nemocnice. Takové požadavky představují zajímavou výzvu, kterou musí naše řešení zvládnout.
Jak se data dostala do tabulky?
Umíme zpětně dohledat, odkud který řádek pochází, jaké tabulky a procesy byly ovlivněny a kam data „doputovala". Komplexitu přidávají další transformace – jako jsou součty, počty nebo vstupy pro AI algoritmy. Logika zpracování se navíc vyvíjí a mění, a proto s našimi zákazníky úzce spolupracujeme, abychom data průběžně ladili a kontrolovali. Při každém nahrání uchováváme metadata, která nám pomáhají rychleji vyřešit případné nesrovnalosti. Může jít o typ nahrání, primární klíče nebo informace o tom, jak byla data deduplikována.
Jak jsme to technicky vyřešili
Abychom dokázali rekonstruovat stav dat k jakémukoli okamžiku – a to bez nutnosti zpracovávat celou historii – ukládáme při každém kroku klíčová metadata: typ nahrání (např. inkrementální vs. úplné), deduplikační pravidla nebo stav dat v daném čase.
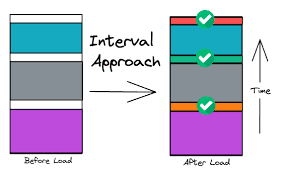
Pokud zákazník požádá o smazání nebo obnovení dat, musíme zohlednit, že data neustále přibývají a mohou ovlivňovat starší i budoucí záznamy. V praxi máme dvě možnosti: Znovu zpracovat celou historii Tento přístup je náročný – vyžaduje detailní znalost starších procesů a s rostoucí historií roste i výpočetní náročnost. Obnovit stav k určitému časovému bodu (Point-in-time recovery) Díky tomu, že při každém ETL běhu ukládáme informace o datech, dokážeme kdykoliv „přetočit" stav dat do konkrétního okamžiku bez nutnosti znovu zpracovat všechna data.
Znovupoužitelné komponenty a nástroje
Vyvinuli jsme interní knihovnu pro sledování původu dat, která našim kolegům poskytuje jednotný způsob dokumentace a větší transparentnost při práci s daty. Zároveň jsme vytvořili modulární a opakovaně použitelné nástroje, které vývojářům ulehčují práci a umožňují týmům rychle řešit požadavky, jako je:
- Mazání nebo obnova dat
- Analýza změn
- Zpětné sledování problémů Pomocí tohoto přístupu zavádíme standardizovaný a robustní systém pro správu dat, který podporuje jak každodenní práci developerů, tak i komplexní požadavky od zákazníků. Touto integrací pomáháme subjektům ve zdravotnictví nejen transformovat data - ale i jim věřit.
Velké díky patří Václavovi Pazderkovi a Filipu Vaššovi, kteří článek napsali a pomohli nám tak s jeho vznikem.




